Cooperative Policy Learning with Pre-trained Heterogeneous Observation Representations
Wenlei Shi1 Xinran Wei2 Jia Zhang1 Xiaoyuan Ni3 Arthur Jiang4 Jiang Bian1 Tie-Yan Liu1
1Microsoft Research 2Beijing University of Posts and Telecommunications 3The Hong Kong University of Science and Technology 4Microsoft ARD Incubation Team
Model
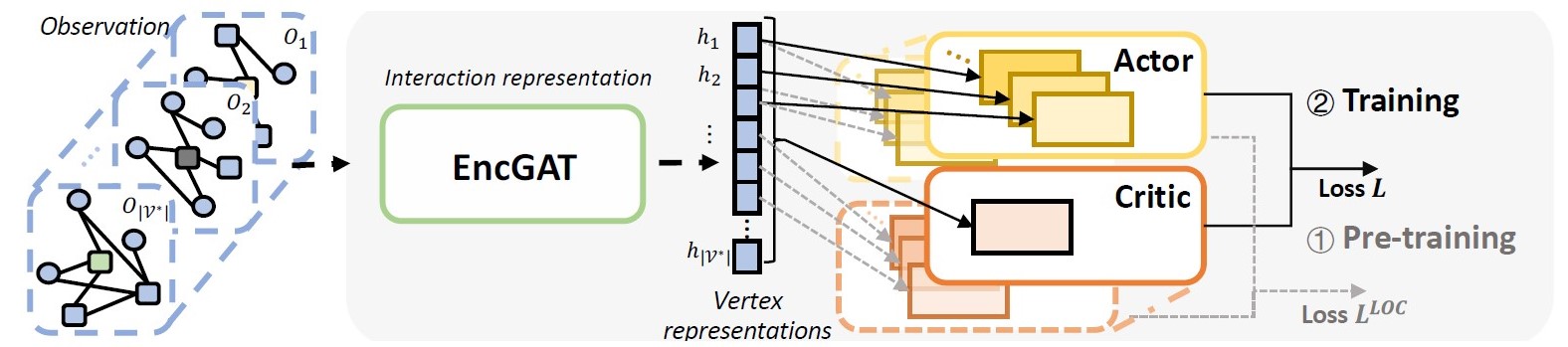
The overall structure of EncGAT-PreLAC. From left to right, it uses EncGAT for interaction representation and feeds the representations to the actor and critic headers. The overall model is first pre-trained with the local loss 𝐿 and then finetuned with a global loss 𝐿 loc.
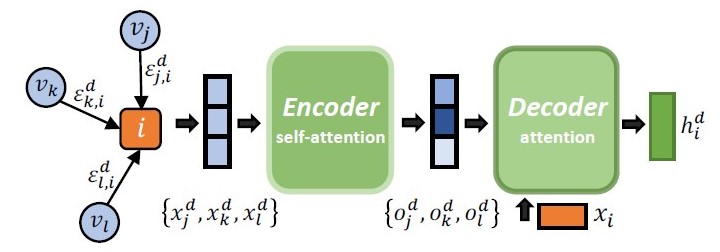
The EncGAT model is designed to efficiently learn informative presentations from the complex interactive graph. The calculation procedure of the encoder is based on self-attention, which is similar to the transformer block. The aggregation among the same type of neighbors is then conducted through the decoder attention. In decoder attention, another scaled dot product attention is applied, which uses the feature vector as the query, and the encoded neighbors’ features matrix as the keys and values.
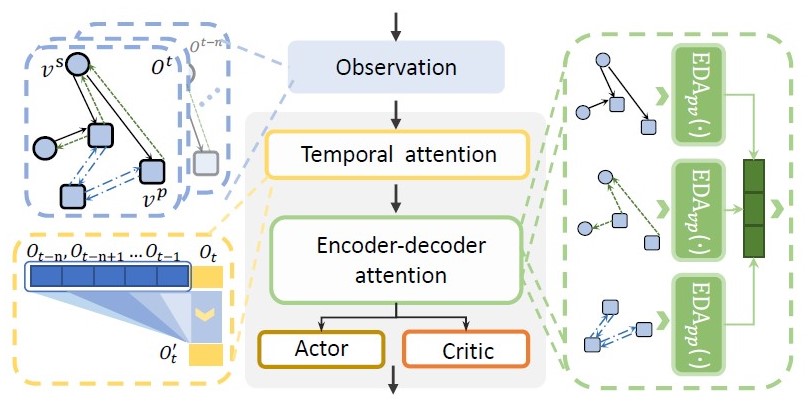
The network structure featured three characteristics based on the problem context of ECR(Empty Containers Repositioning). Firstly, it used the temporal attention to capture features of the sequential input. Secondly, we concatenate the edge features with neighbors before feeding it to EncGAT. Thirdly, both the port and the vessel features are fed into the action head. Finally, we stack two encoder-decoder attentions in the EncGAT and residual connections are used to prevent over-smoothing. The actor and critic headers consist of two fully-connected layers also with residual connections. We share the headers of actor and local critic between agents, which makes the overall framework inductive.
More details of our model structure can be found in the MARO Platform. Full paper and oral presentation accepted by AAMAS-2021
Experiment
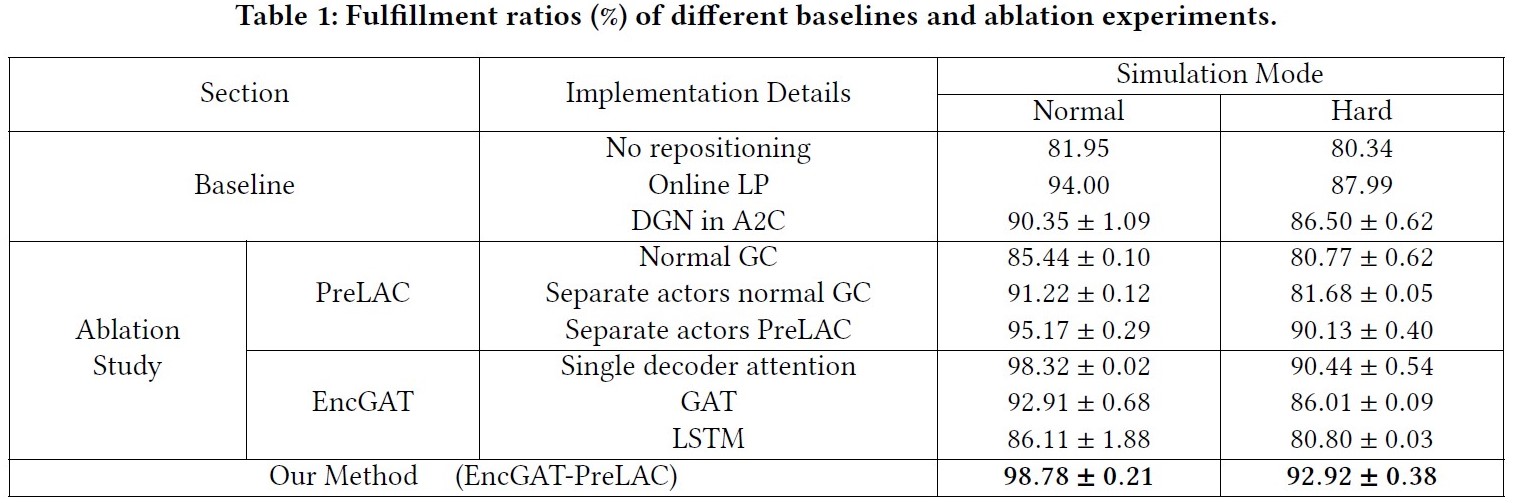
Baseline Comparison
We compare our framework with existing baseline methods with the total fulfillment ratio,
that is the ratio of fulfilled demands to all demands, as the evaluation metric.
Ablation Study
We also conduct the ablation studies to answer:
- Does the encoder-decoder attention in EncGAT help heterogeneous information aggregation and intricate interaction understanding?
- Does PreLAC improve learning performance of cooperative policy?

Visualization of vertex embeddings in global-critic (a) and our method (b). The color identifies different ports and each point represents a feature vector in a batch.
Order proportion distribution between two ports in the original topology (a) and the new topology (b). Each column represents the proportions of orders from one port to orders. Note that two merged ports are the 9th and 10th columns.