Semi-Supervised Few-Shot Atomic Action Recognition
✝Xiaoyuan Ni1 ✝Sizhe Song1 Yu-Wing Tai2 Chi-Keung Tang1
1The Hong Kong University of Science and Technology
2Kuaishou
✝Equal Contribution
Model
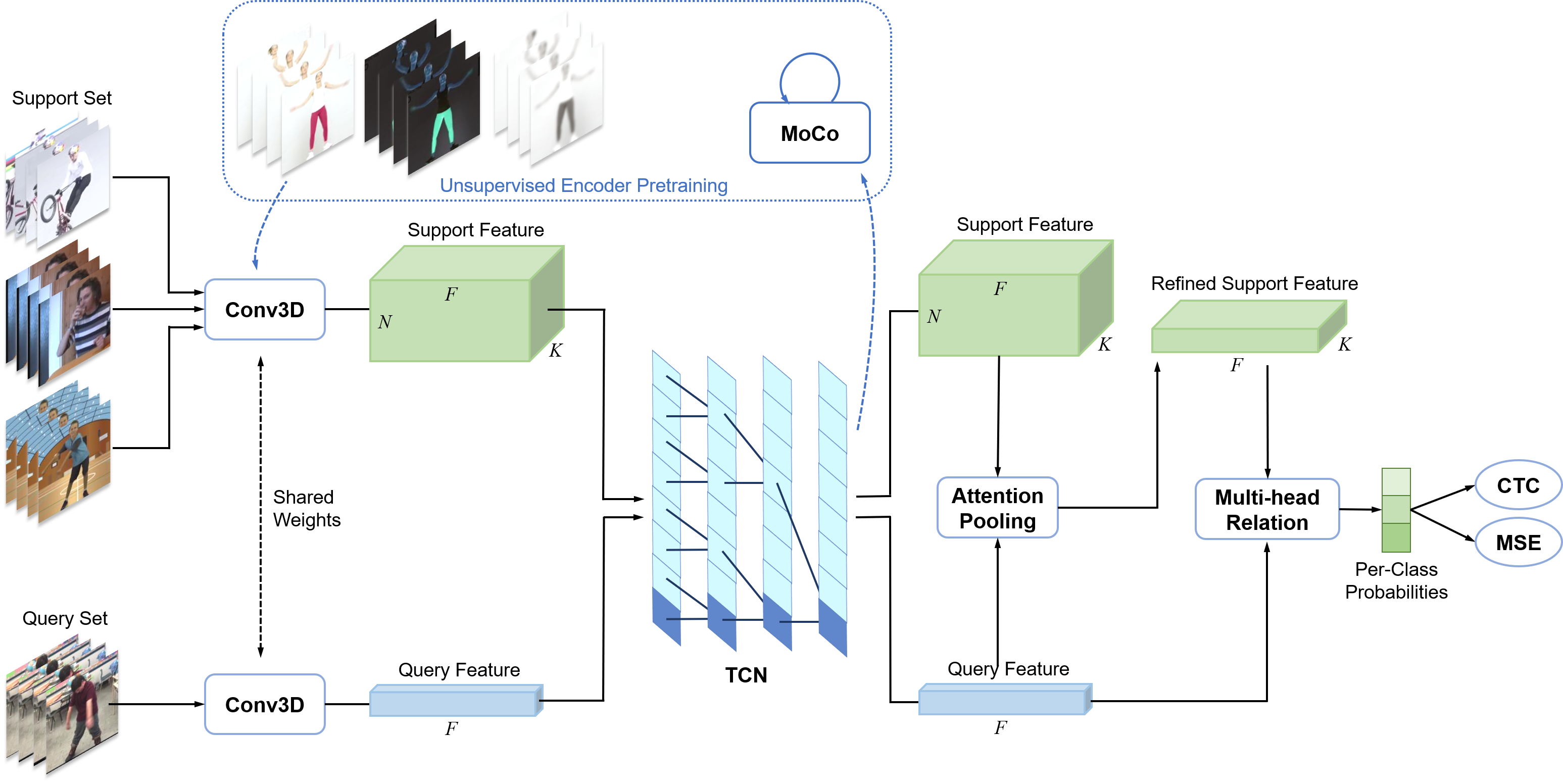
Model Architecture. Our learning strategies are divided into two parts: 1) train an encoder with unsupervised learning; 2) train the action classification module with supervised learning. Regarding the encoder our model provides fine-grained spatial and temporal video processing with high length flexibility, which embeds the video feature and temporally combines the features with TCN. In terms of classification module, our models provides attention pooling and compares the multi-head relation. Finally, the CTC and MSE loss enables our model for time-invariant few shot classification training.



Action Augmentation. We use three action augmentation methods in this project: 1) Background Subtraction (left); 2) Human-centric (top right); 3) Usual Image Augmentation (bottom right). The augmented action and original action are used to train an encoder with unsupervised learning. It helps the encoder to focus on foreground movement and human bodies.
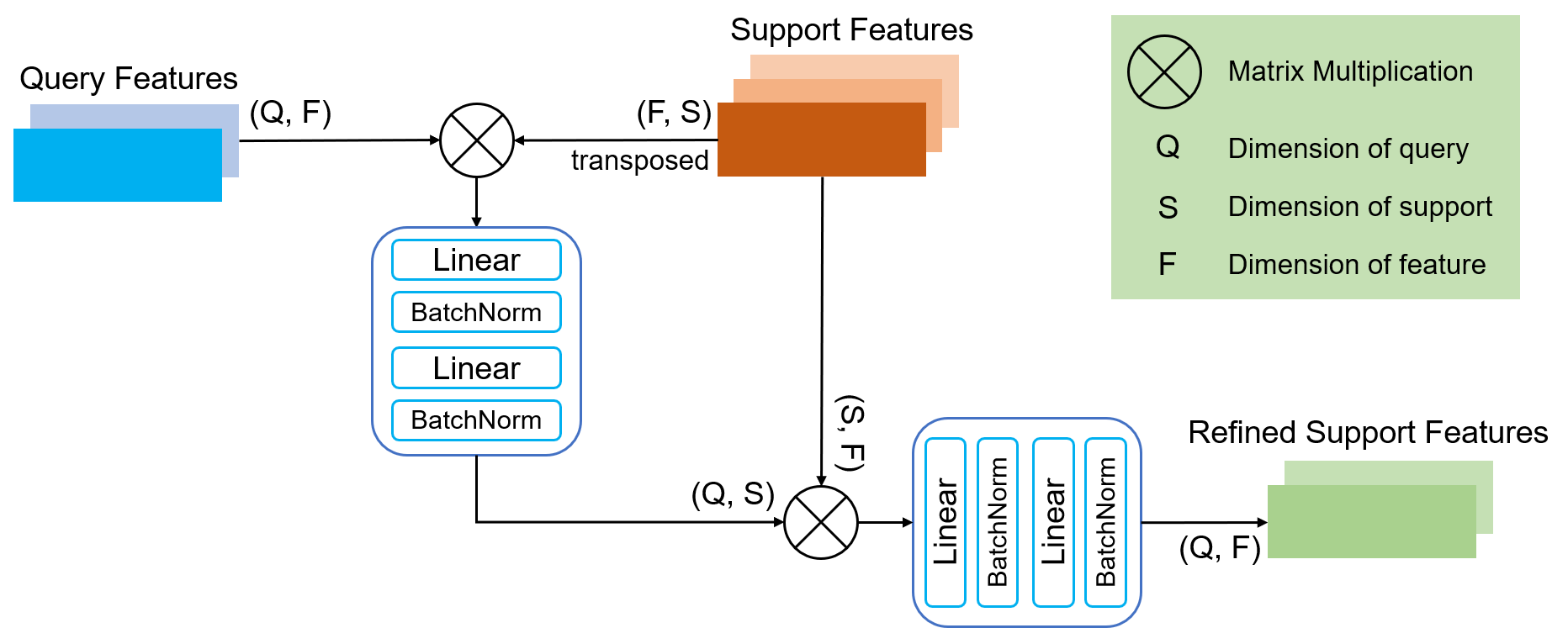
Attention Pooling is a module to compress and refine support features. Different with traditional self-attention, we introduce query feature into the pooling procedure to generate "customized" support for each query. Also, we can simply swap support and query so that this module can be used to refine query feature, which we call mutual refinement.
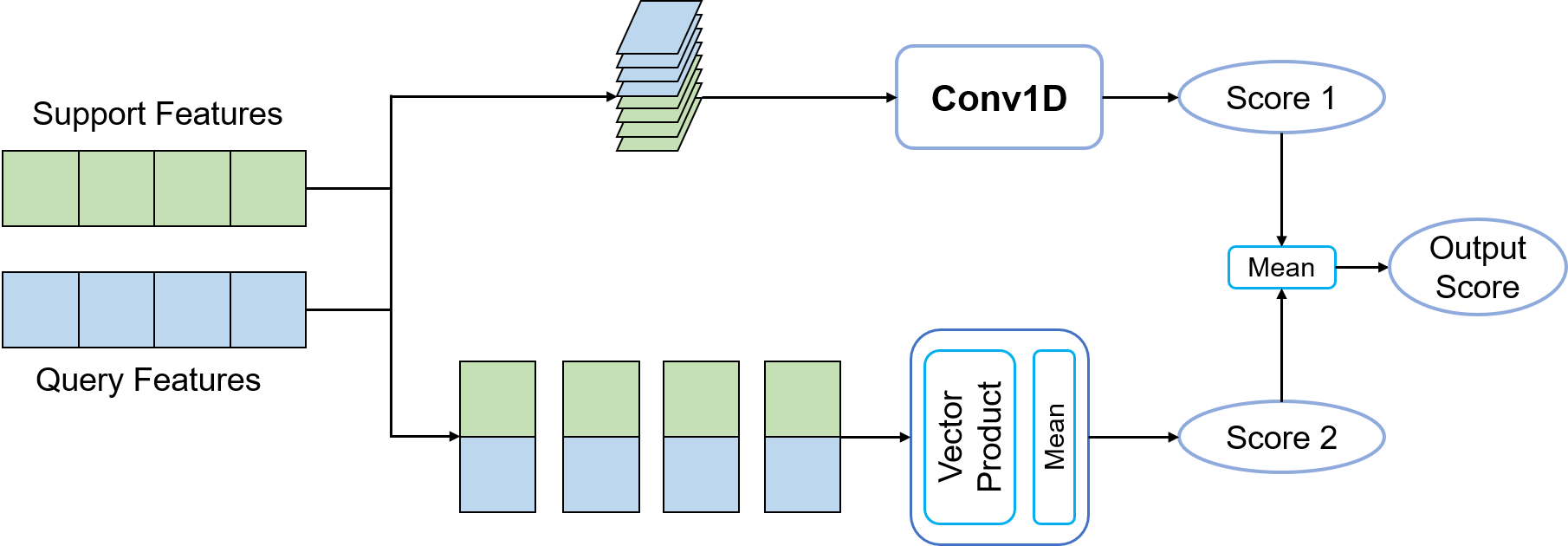
Multi-head Relation Network is a module to compute the similarity between supports and queries. The final score is an average of two, one from vector product and another from a Conv1D. The first one focuses more on localized feature, the second one takes a comprehensive analysis of the entire feature.
Experiment
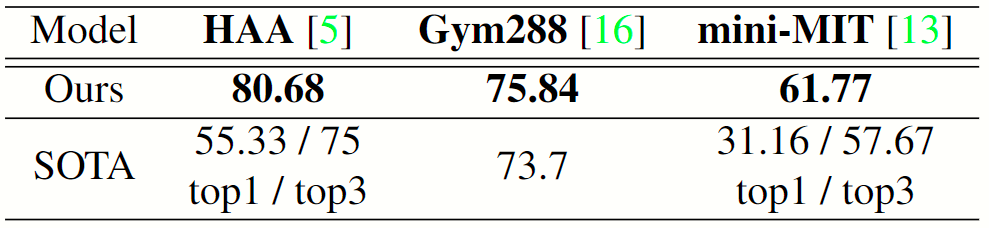
Accuracy (%) of our model compared with other state-of-the-art methods on three datasets, which shows that our few-shotmodel has a leading performance compared with the state-of-the-art methods on all the three datasets trained in fullsupervision. Note that our model is few-shot which has ac-cess to only very limited amount of data.
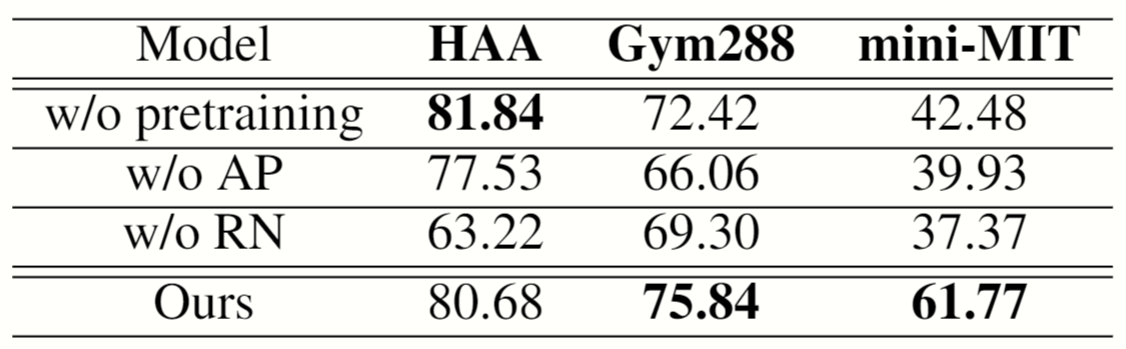
Ablaton Study. The unsupervised action encoder may experience relatively less accuracy drop in human-centric datasets such as HAA where the action features are better aligned. However, on more general datasets, the human-centric augmentation shows greater importance and the ablation accuracy drops significantly on mini-MIT. Besides, the performance on HAA and Gym288 drops less compared with that on mini-MIT, indicating our model's better representativeness over a general set of action data.